Data¶
Vi laget et Python-script som hentet ned data fra Oslo bysykkels API hvert 15. minutt 16. til 26. august 2018. Vi satte en timestamp for hver gang vi hentet ned dataene, og lagret disse dataene til en stor JSON-fil.
I JSON-filene ligger dataene lagret som objekter, hvor nøkkelen er en timestamp, og verdien er en array med rådataene fra Oslo bysykkels API.
Oppsett¶
Vi bruker pakkene shapely, shapely_geojson, matplotlib, pandas og seaborn utover standardbibliotekene til Python 3.
%%javascript
IPython.OutputArea.auto_scroll_threshold = 1000;
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import display, Markdown
import seaborn; seaborn.set()
import json, datetime
import pandas as pd
pd.set_option("display.max_rows",240)
from shapely.geometry import Point
from shapely_geojson import dumps, Feature, FeatureCollection
def convert_ts(ts):
dt = datetime.datetime.fromtimestamp(ts)
return dt.isoformat() + 'Z'
Datainnhenting og strukturering¶
Vi laster inn dataene fra skrapejobben, og lager tomme objekter og arrays som skal inneholde de ulike masserte utgavene av dataene
j = json.load(open('../data/bysykkel.json'))
Vi traverserer over rådataene og strukturerer dem i ulike bøtter. stativer brukes for å restrukturere rådataene til et format som passer bedre for GeoJSON, et format tilpasset analyse i kartverktøy som programmet QGIS. features er en array av GeoJSON-features som kan brukes til QGIS-analyse. structured er en struktur som passer fint for å få dataene inn i pandas.
stativer = {}
features = []
structured = []
for key, items in j.items():
for item in items:
if not 'lat' in item.keys():
continue
structured.append([float(key), item['title'], item['id'], item['lat'], item['lng'], item['availability']['bikes'], item['availability']['locks']])
if not item['id'] in stativer.keys():
stativer[item['id']] = [{'time': key, 'data': item}]
continue
stativer[item['id']].append({'time': key, 'data': item})
for bike_rack, items in stativer.items():
for item in items:
if not 'lat' in item['data']:
continue
tmp = Feature(Point(item['data']['lng'], item['data']['lat']), {"name": item['data']['title'], "timestamp": convert_ts(float(item['time'])), "id": bike_rack, "bikes": item['data']['availability']['bikes'], "locks": item['data']['availability']['locks']})
features.append(tmp)
feature_collection = FeatureCollection(features)
with open('bysykkel_total.geojson', 'w') as fp:
fp.write(dumps(feature_collection))
Lemp dataene inn i pandas for videre analyse. pandas er fint, og gjør det enkelt å lage noen hjelpsomme kolonner fra dataene. Vi lager følgende kolonner:
timerestruktureres til en datetime-kolonnedatelager en datokolonne fra `time``hourer timen på døgnet for den aktuelle radenday_of_weeker et tall mellom 0-6 for hvilken ukedag det er snakk om (mandag = 0)hour_minuteer HH:MM som en tekst-streng
df = pd.DataFrame(structured, columns="time title id lat lng bikes locks".split())
df['time'] = pd.to_datetime(df['time'], unit="s")
df['date'] = df['time'].dt.date
df['hour'] = df['time'].dt.hour
df['day_of_week'] = df['time'].dt.dayofweek
df['hour_minute'] = df.time.apply(lambda x: "%s:%s" % (x.hour, x.minute))
pandas lager vanligvis en indeks på dataene som lempes inn, men vi setter time-kolonnen til indeks for å enkelt kunne skrelle vekk data som vi ikke ønsker.
Vi startet innhøstingen onsdag 15. august, midt på dag, så vi dropper alt som er før 16. august, og alt som er etter 26. august.
df = df.set_index('time')
df = df['2018-08-16':]
df = df[:'2018-08-26']
Bysykkel-systemet er stengt mellom midnatt og 06:00, så vi skreller bort alle rader i de tidsrommene fra dataframen vår. Etter at det er gjort resetter vi indeksen tilbake til ID, siden pandas sliter med en del spørringer der indeksene ikke er unike.
# Dropp rader mellom midnatt og 06:00. Da er bysykkel-tjenesten stengt
df = df.between_time('06:00', '00:01')
df = df.reset_index()
Vi lager to subframes som inneholder henholdsvis ukedager og helger (weekdays og weekends), for å kunne analysere hvorvidt det er store forskjeller i tilgjengelighet mellom disse.
weekdays = df.loc[df.day_of_week < 5]
weekends = df.loc[df.day_of_week >= 5]
Hjelpefunksjoner¶
lookup_day og random_sample er to hjelpefunksjoner som lager hhv. dags- og fulldatagrafer over antall ledige sykler og låser på et tilfeldig utvalg av stativer.
sample_size avgjør hvor mange stativer som plukkes ut av datasettet.
Funksjonene show_day og show_total viser tilgjengelige sykkellåser og sykler i grafer. 'lookup_day' gir en graf per dag.
def lookup_day(day="Sunday", sample_size=10):
for i, sample in df.sample(n=sample_size).iterrows():
display(Markdown("# %s" % sample['title']))
grouped_by_date = df.loc[df['id'] == sample['id']].groupby(df['date'])
for name, group in grouped_by_date:
if not list(group['time'].dt.weekday_name)[0] == day:
continue
#display(Markdown("## %s (%s)" % (name, list(group['time'].dt.weekday_name)[0])))
plot = group[['hour', 'bikes', 'locks']].plot(kind="line", x='hour', title="%s (%s)" % (name, list(group['time'].dt.weekday_name)[0]), ylim=(-10,max(df.bikes.max(), df.locks.max())), figsize=(15,6))
plt.show()
def random_sample(sample_size=3):
for i, sample in df.sample(n=sample_size).iterrows():
display(Markdown("# %s" % sample['title']))
grouped_by_date = df.loc[df['id'] == sample['id']].groupby(df['date'])
for name, group in grouped_by_date:
#display(Markdown("## %s (%s)" % (name, list(group['time'].dt.weekday_name)[0])))
plot = group[['hour', 'bikes', 'locks']].plot(kind="line", x='hour', title="%s (%s)" % (name, list(group['time'].dt.weekday_name)[0]), xlim=(0,23), ylim=(-10,max(df.bikes.max(), df.locks.max())), figsize=(15,6))
plt.show()
def show_day(stativnavn="Grenseveien"):
"""
Generate daily plots of number of bikes and locks on a location.
"""
display(Markdown("# %s" % stativnavn))
tmp = df.loc[df['title'] == stativnavn]
grouped_by_date = tmp.groupby(df['date'])
for name, group in grouped_by_date:
g = group
group[['hour', 'bikes', 'locks']].plot(x='hour', xlim=(6,24), title="%s (%s)" % (name, list(g['time'].dt.weekday_name)[0]), figsize=(15,7))
plt.show()
def show_total(stativ):
"""
Display a total plot of the bikes and locks on a location.
"""
tmp = df.loc[df['title'] == stativ][['time', 'bikes', 'locks']].plot(x='time', title=stativ, figsize=(15,7))
plt.show()
Analyse av datasettet¶
Hvor ofte er stativene tomme?¶
Det er altså en rekke stativer som er ofte tomme, men hvor stor andel av tiden er de tomme og hvilke stativer er verst?
Vi grupperer dataene etter stativets ID, og sjekker hvor stor del av tiden det aktuelle stativet har sykler.
tomme_stativer = []
# Grupperer datasettet etter id.
for i, group in df.groupby('id'):
tmp = group['bikes'].value_counts(normalize=True).sort_index()
tomme_stativer.append([int(group['id'].values[0]), group['title'].values[0], group['lat'].values[0], group['lng'].values[0], tmp.values[0]*100])
tomme_stativer_df = pd.DataFrame(tomme_stativer, columns="id title lat lng empty".split())
tomme_stativer_df = tomme_stativer_df.sort_values('empty', ascending=False)
Antall stativer som er tomme 50% av tiden eller mer:¶
tomme_stativer_df.loc[tomme_stativer_df['empty'] >= 50]['id'].count()
Antall stativer som er tomme under 50% av tiden:¶
tomme_stativer_df.loc[tomme_stativer_df['empty'] < 50]['id'].count()
Liste over de ti stativene som er oftest tomme i Oslo:¶
tomme_stativer_df.sort_values('empty', ascending=False).head(10)
Liste over de stativene som er sjeldnest tomme i Oslo¶
tomme_stativer_df.sort_values('empty', ascending=True).head(10)
tomme_stativer_df inneholder antall prosent hvor de ulike stativene har 0 tilgjengelige sykler. Vi lager en ny GeoJSON-fil som vi kan bruke for å visualisere hvor ofte stativene er tomme 50% av tiden eller mer.
tomme_stativer_features = []
for id, title, lat, lng, empty in tomme_stativer:
tmp = Feature(Point(lng, lat), {"name": item['data']['title'],"id": id, "empty": empty})
tomme_stativer_features.append(tmp)
tomme_stativer_featurecollection = FeatureCollection(tomme_stativer_features)
with open('tomme_stativer.geojson', 'w') as fp:
fp.write(dumps(tomme_stativer_featurecollection))
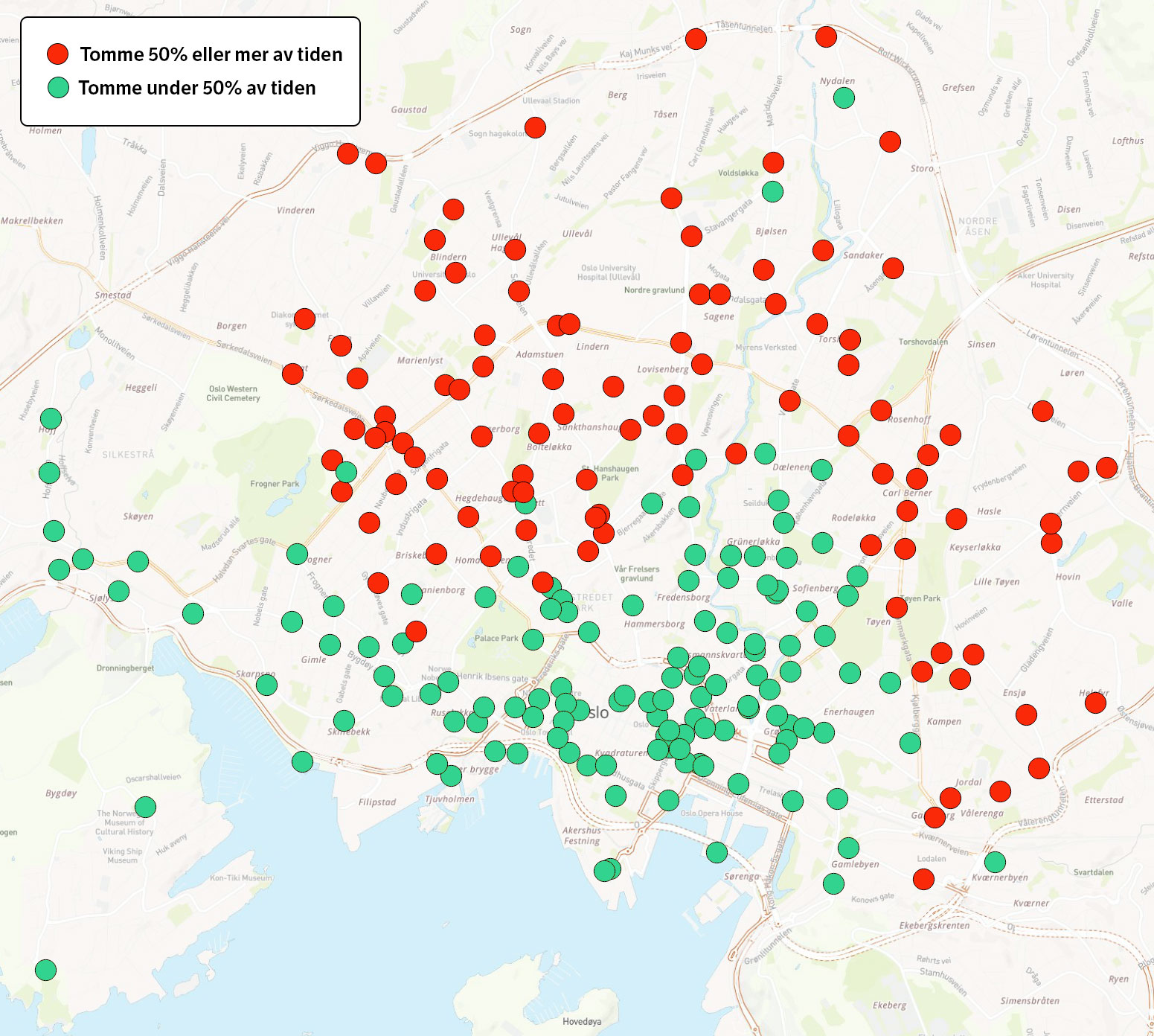
Kart eksportert fra QGIS¶
Det kommer her fram at sentrum av Oslo, Frogner, og Grunerløkka er de stedene hvor syklene er mest tilgjengelige.
Hvordan ser tilgjengeligheten ut for et sykkelstativ over tid?¶
Thereses gate, som ligger ved St. Hanshaugen, er det stativet som oftest er tomt i Oslo etter vår toppliste. Hvordan ser bruken ut i en graf?
show_total('Thereses gate')

Hva skjer om vi lager en graf for hver dag, får vi vite noe mer da?¶
Svar: Som oftest er det ingen sykler, men når det kommer noen til stativet forsvinner de ofte innen det har gått én time.
show_day("Thereses gate")











Hvordan ser det ut på Oslos minst tomme stativ?¶
Svar: Lars Vaular ville sagt "opp og ned som en sprettball". Stoppet er tomt for sykler en gang, og er noen ganger ingen ledige sykkellåser i helgene.
show_total("Sjøsiden vest")
show_day("Sjøsiden vest")












I hvilken grad er det en forskjell mellom helg og ukedager?¶
Svar: Antall stativer med tilgjengelige sykler er høyere i ukedagene enn i helgene.
tomme_stativer_weekends = []
# Grupperer datasettet etter id.
for i, group in weekends.groupby('id'):
tmp = group['bikes'].value_counts(normalize=True).sort_index()
tomme_stativer_weekends.append([int(group['id'].values[0]), group['title'].values[0], group['lat'].values[0], group['lng'].values[0], tmp.values[0]*100])
tomme_stativer_weekends_df = pd.DataFrame(tomme_stativer_weekends, columns="id title lat lng empty".split())
tomme_stativer_weekends_df = tomme_stativer_weekends_df.sort_values('empty', ascending=False)
tomme_stativer_weekdays = []
# Grupperer datasettet etter id.
for i, group in weekdays.groupby('id'):
tmp = group['bikes'].value_counts(normalize=True).sort_index()
tomme_stativer_weekdays.append([int(group['id'].values[0]), group['title'].values[0], group['lat'].values[0], group['lng'].values[0], tmp.values[0]*100])
tomme_stativer_weekdays_df = pd.DataFrame(tomme_stativer_weekdays, columns="id title lat lng empty".split())
tomme_stativer_weekdays_df = tomme_stativer_weekdays_df.sort_values('empty', ascending=False)
tomme_stativer_status = {
'helger': {
'tomme mer enn 50% av tiden': tomme_stativer_weekends_df.loc[tomme_stativer_weekends_df['empty'] >= 50]['id'].count(),
'tomme mindre enn 50% av tiden': tomme_stativer_weekends_df.loc[tomme_stativer_weekends_df['empty'] < 50]['id'].count()
},
'ukedager': {
'tomme mer enn 50% av tiden': tomme_stativer_weekdays_df.loc[tomme_stativer_weekdays_df['empty'] >= 50]['id'].count(),
'tomme mindre enn 50% av tiden': tomme_stativer_weekdays_df.loc[tomme_stativer_weekdays_df['empty'] < 50]['id'].count()
}
}
tomme_stativer_status = pd.DataFrame(tomme_stativer_status)
tomme_stativer_status.plot.bar(figsize=(15,8), rot=0)
plt.show()

Antall stativer i helga som er helt tomme 50% av tiden eller mer:¶
tomme_stativer_weekends_df.loc[tomme_stativer_weekends_df['empty'] >= 50]['id'].count()
Antall stativer i helga som er helt tomme under 50% av tiden:¶
tomme_stativer_weekends_df.loc[tomme_stativer_weekends_df['empty'] < 50]['id'].count()
Antall stativer i ukedagene som er helt tomme 50% av tiden eller mer:¶
tomme_stativer_weekdays_df.loc[tomme_stativer_weekdays_df['empty'] >= 50]['id'].count()
Antall stativer i ukedagene som er helt tomme under 50% av tiden:¶
tomme_stativer_weekdays_df.loc[tomme_stativer_weekdays_df['empty'] < 50]['id'].count()
Hvor mange sykler er det vanligvis i stativet?¶
Vi tar en random sample på 30 rader fra df, og teller hvor mange ledige sykler det til enhver tid er på de ulike stativene.
for i, sample in df.sample(n=30).iterrows():
df.loc[df['id'] == sample['id']]['bikes'].value_counts().sort_index().plot(kind='bar', figsize=(15,5), title=sample['title'])
plt.show()





























Svar: Majoriteten av stativene oppgir at de har et høyt antall målinger med null sykler i stativet.
Hvor mange sykkelstativer har på et tidspunkt vært tomme?¶
all_bikes = df.groupby('id')
all_bikes[['title', 'bikes']].aggregate(min).sort_values('bikes')['bikes'].value_counts()
Svar: Alle stativer bortsett fra ett har i løpet av perioden vært tomme.